Tilde 3.0 ModelForge
Written By Team ModelForgeEnter ModelForge! A low code ML platform
Authors: Kavya, Kusuma, Manit, Shreeya, Yashmitha
Contents
Introduction
Picture this: You are a visionary artist with a masterpiece in mind-you know exactly what you want to do,what paints and brushes you need, all you have to do is get it out of your head and onto a canvas, But your workspace is cluttered. Everything is everywhere, and every time you try to start, you waste hours just trying to find your tools.
Enter Modelforge - A low code platform!
Just input in your Machine Learning model idea and abracadabra-You have your model. Cool isn't it?
ModelForge was created for all the artists in the machine learning world — data scientists,and ML engineers-who need a streamlined, efficient, and scalable way to paint up their machine learning creations.
Just like a neural network needs its neurons to function, ModelForge needed a blend of Python libraries, each one connecting us closer to our goal, one ‘synapse’ at a time.
Contributors:
Mentors:
Working of ModelForge
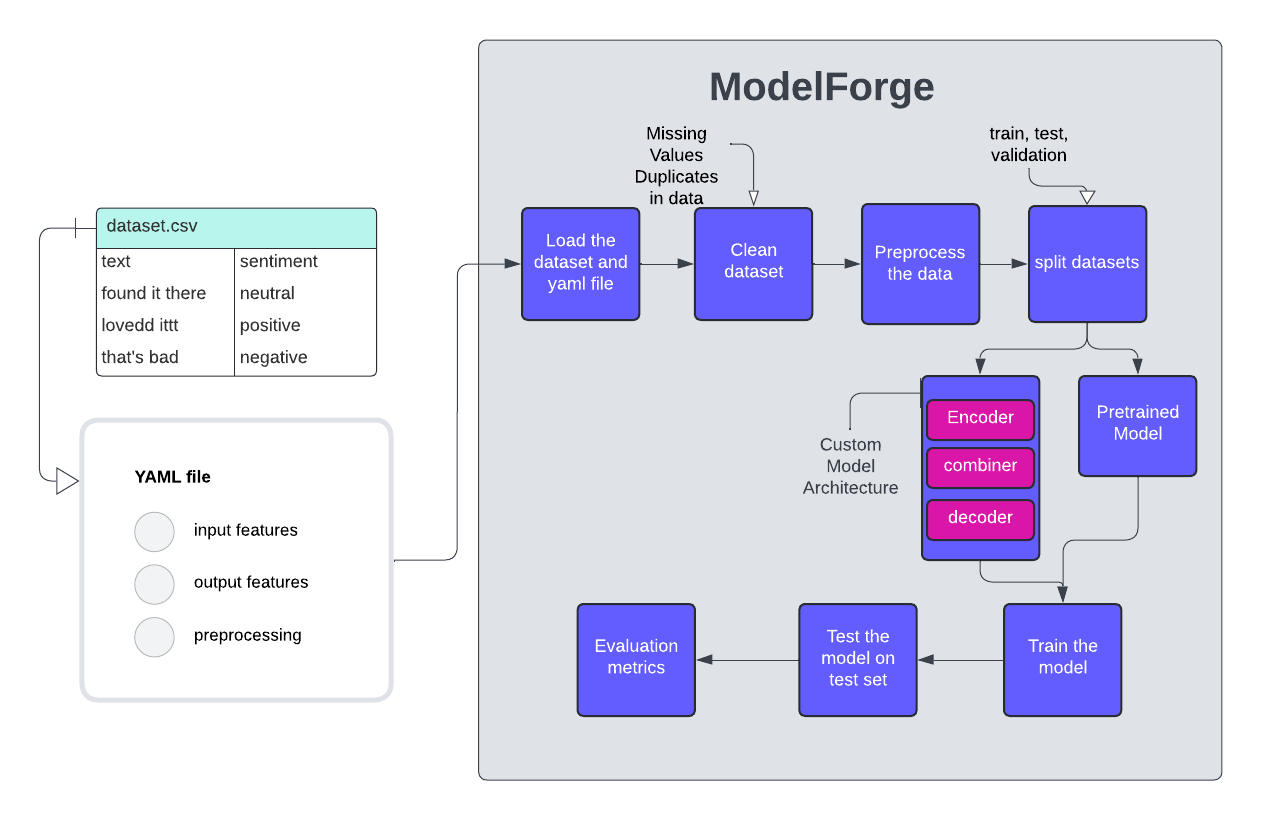
The flowchart above explains how ModelForge transforms raw data into meaningful results .From loading the YAML configuration file to cleaning and preprocessing dataset all the way through to testing with our custom models and evaluating the results—this visual guide showcases each step in our streamlined data pipeline.
Let’s explore some of these step by step:
LOADING DATASET AND YAML FILE
The first step in our pipeline involves loading the dataset and yaml configuration file which contains crucial parameters that are plugged in according to your model’s needs. This ensures that all subsequent steps are executed according to the specified parameters, streamlining the workflow and making it easier to manage different data processing requirements. 
DATA CLEANING
Handling missing values, automatically detect and remove or substitute them so that your model gets a full picture of your data avoiding skewness.
DATA PREPROCESSING
Just like we prefer conversations that flow naturally without the need to decode every word , models also thrive when they are given clear, structured data. That’s where preprocessing comes in—it’s the process of refining raw data into a form that is easier for models to understand and work on. ModelForge helps automate these steps for you and saves your time to ensure your data is model-ready. Here’s how we make that happen:
- Tokenization: divides sentences into smaller units-words,subwords or characters-so that models can process more effectively.
Sentence: “We all love ModelForge” Tokenization: [“We”, “all”, “love”, “ModelForge”] (ofcourse :D)
- Normalization and scaling: A single variable shouldn’t dominate the model’s learning process.Flexible feature scaling options like standard normalization and MinMax scaling, depending on your model’s needs, can be used.
- Text cleaning: Removing unnecessary characters to make the data uniform for the models-punctuations and stop words- and also stemming to get the root words.
DATA SPLITTING:
After cleaning and preprocessing of dataset,we split it into test, train and validation sets. This step ensures that we have separate subsets of the data to train our model and evaluate its performance.
The Model Architecture
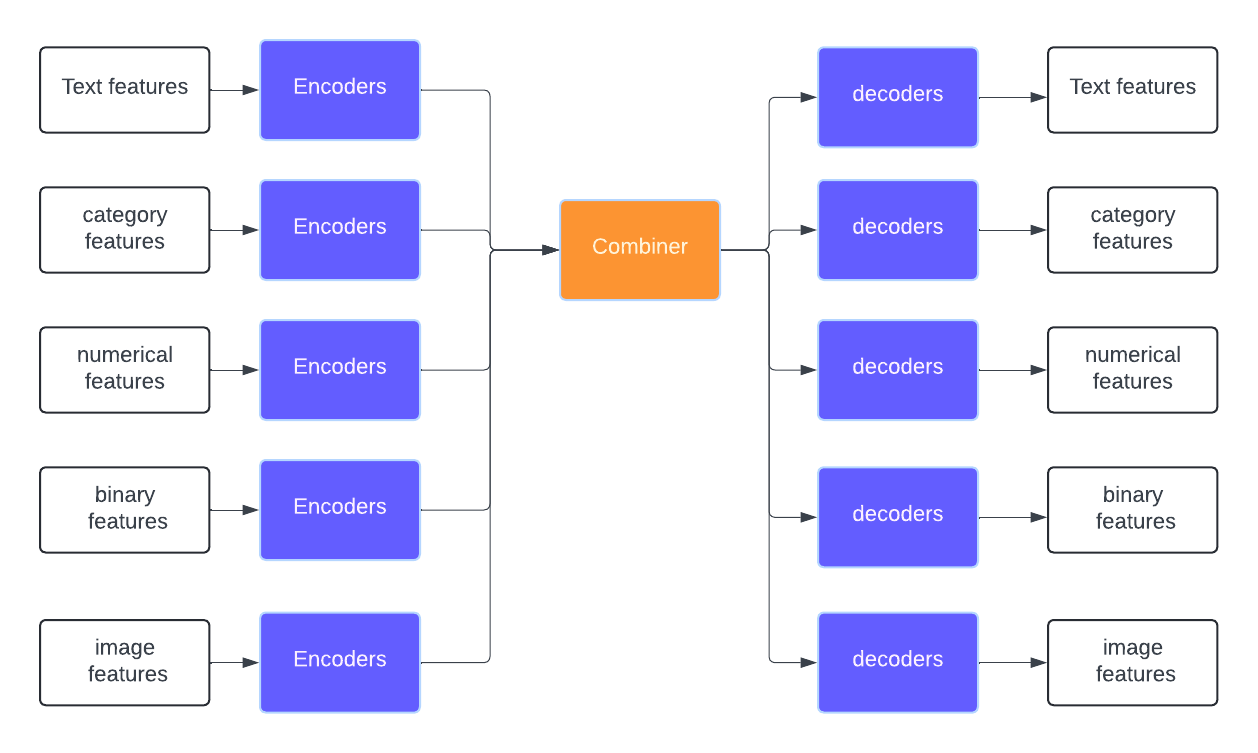
We provide users with the flexibility to use custom model architectures instead of relying solely on prebuilt models like BERT or RoBERTa. Our project’s model architecture is composed of an encoder, combiner and decoder. Depending on the type of Machine Learning problem, the appropriate encoders and decoders are selected. This modular approach allows for greater customization and adaptability, enabling users to implement the most suitable architecture for their needs. Refer the diagram below to visualize better.
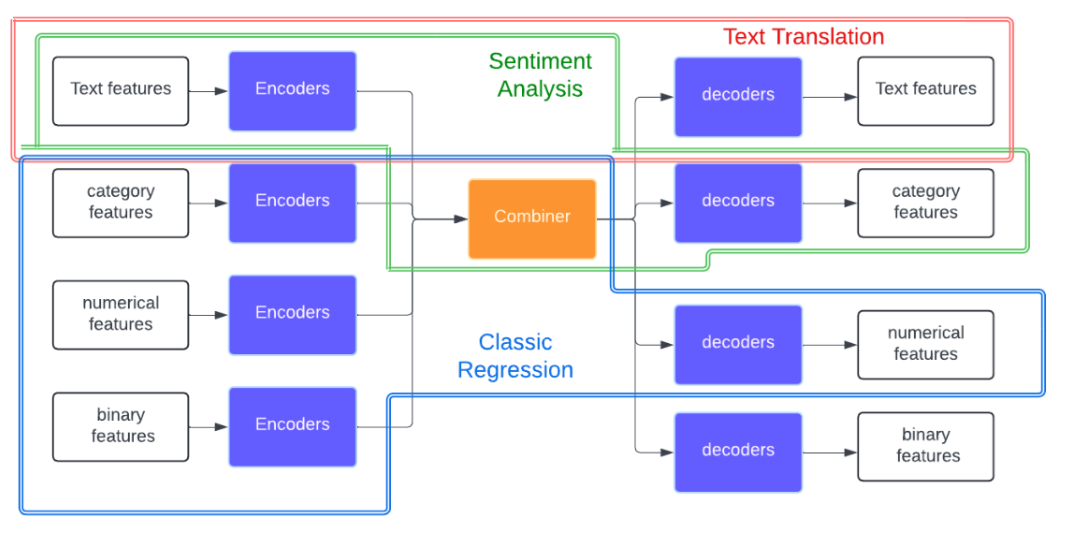
- Text translation & Text summarization:
input->textoutput->text - Sentiment Analysis & News classification:
input->textoutput->category - Classic Regression:
input->category, numeric, binaryoutput->numeric
This is how the model architecture adapts various machine learning tasks by selecting appropriate encoders and decoders based on the input and output requirements
Encoder
An encoder transforms raw data into a compressed or lower-dimensional representation, capturing the essential information from the input data.
Combiner
When dealing with multiple input features, each feature may require a different encoder. The combiner merges these diverse representations into a unified format. It also enables the model to learn complex features from different inputs, gradually improving overall performance.
Decoder
The decoder takes this combined representation and transforms it into the desired output format. For classification tasks, the decoder might consist of fully connected layers that map the combined representation to class probabilities. For tasks like text generation, it could generate sequences of text.
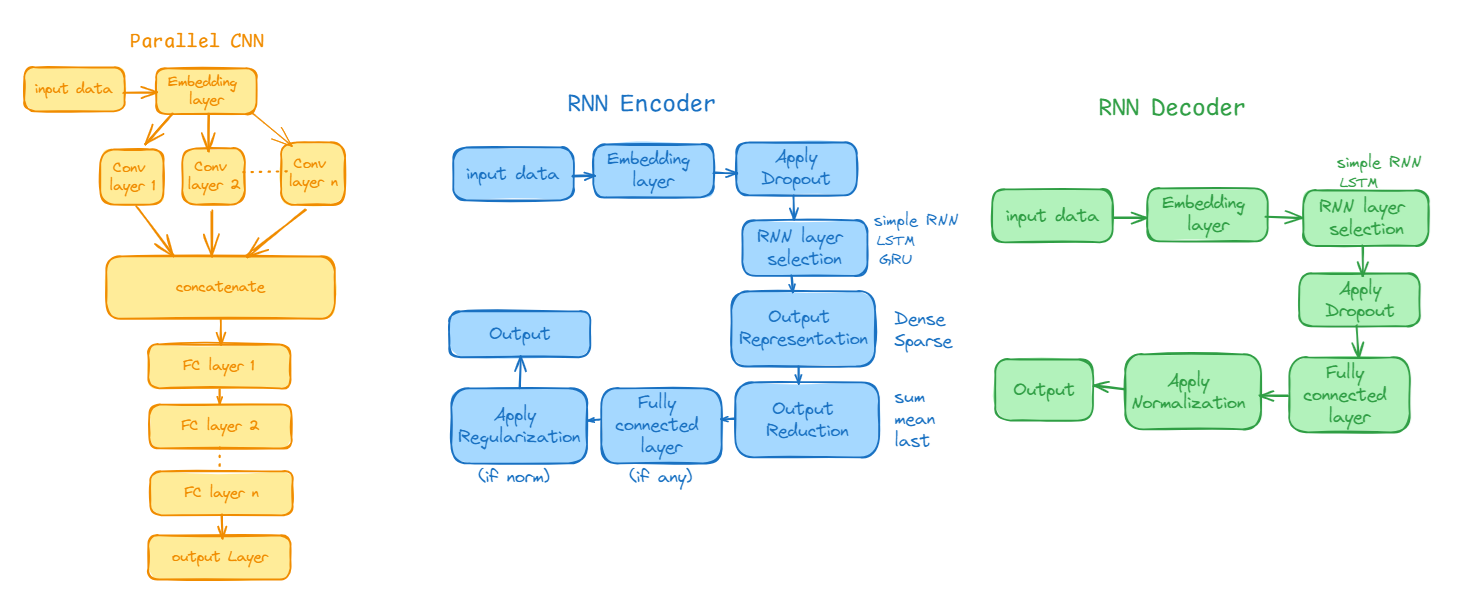
Here is the list of encoders and decoders we have worked on
| Data type | Encoders | Decoders |
|---|---|---|
| text | RNN, ParallelCNN, Transformer | RNN, Transformer |
| category | OneHot encoding, label encoding | Inverse Transform |
| numeric | Min-Max Scaling, Standard scaling | Inverse Transform |
Mechanism of Encoder-Decoder Architecture
 Transformer Model (Based on paper: Attention Is All You Need)
Transformer Model (Based on paper: Attention Is All You Need) This is how the final model architecture looks 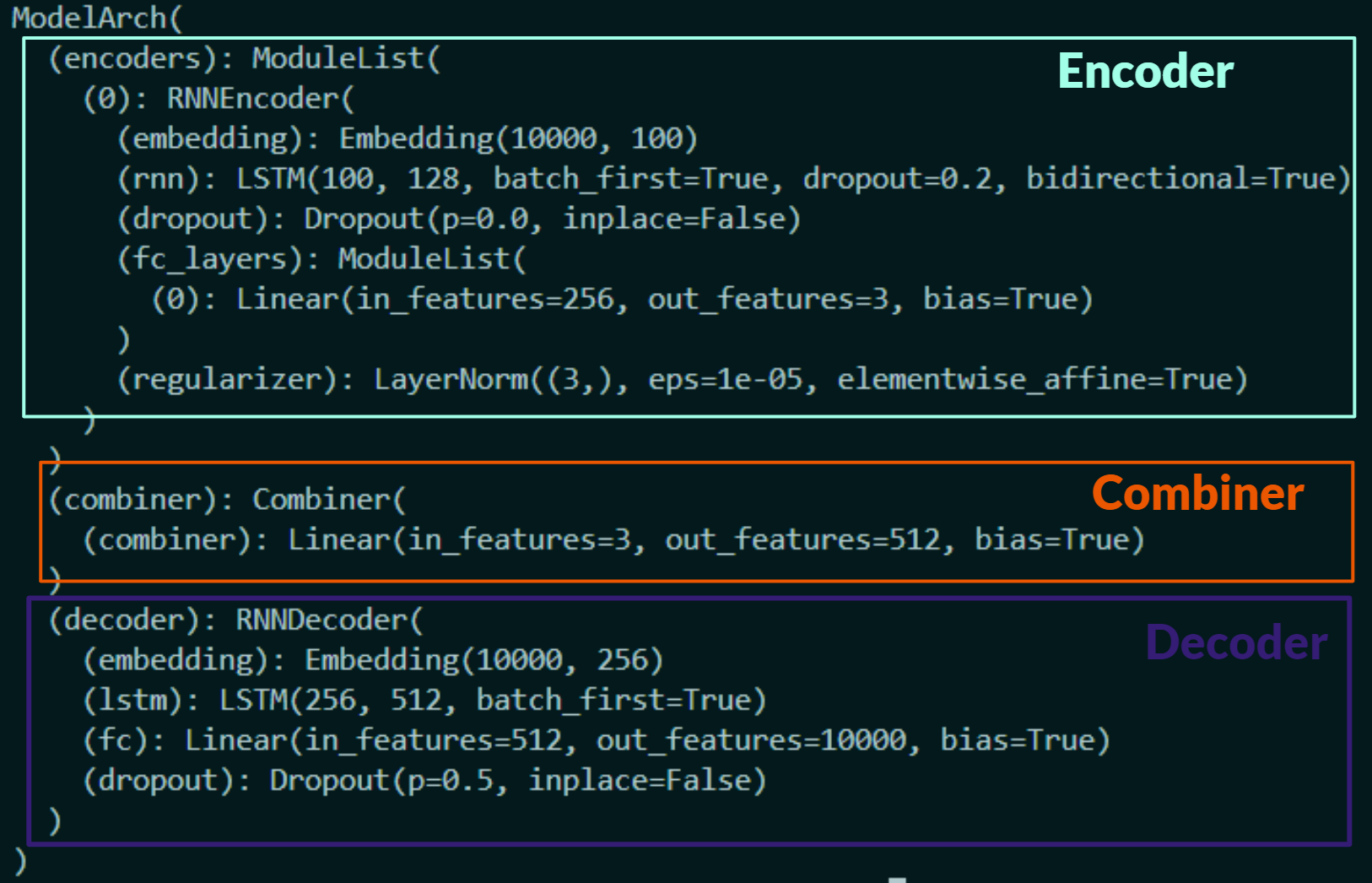
ML Flow
We wanted to visualise the training and testing data, to do that we used MLflow, an open-source platform that helps with managing the end-to-end machine learning lifecycle. Mlflow helps with
- Experiment Tracking
- Model Management
- Deployment and Scalability
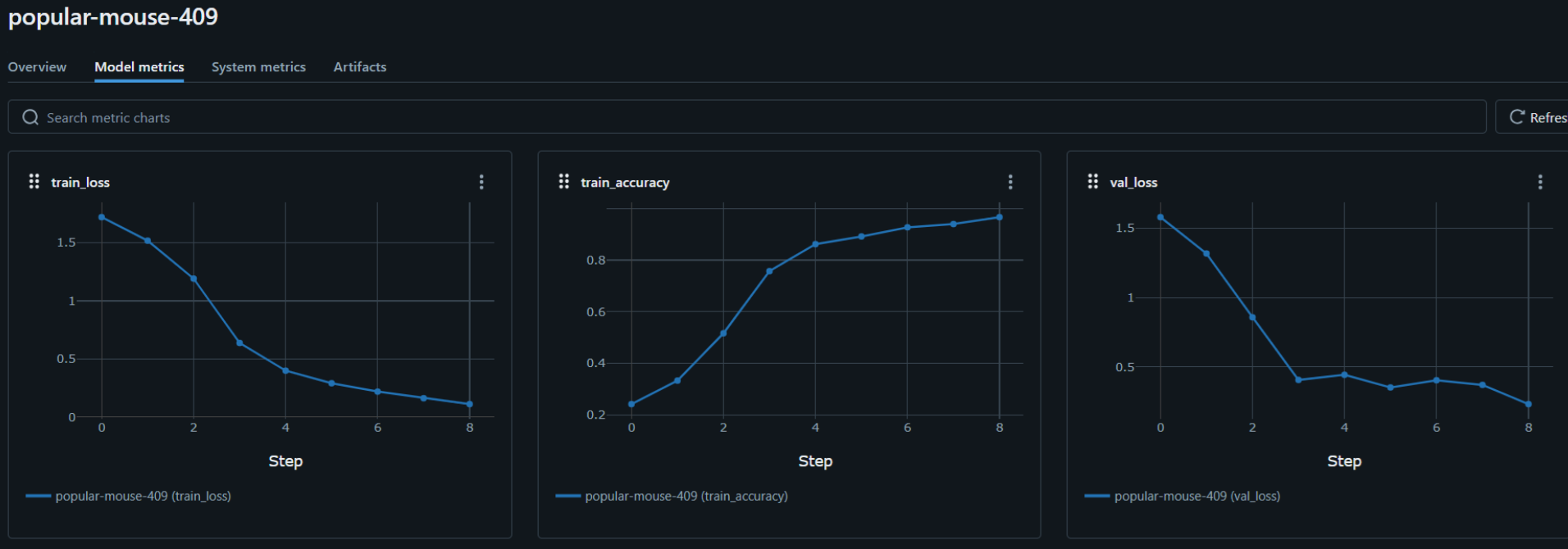
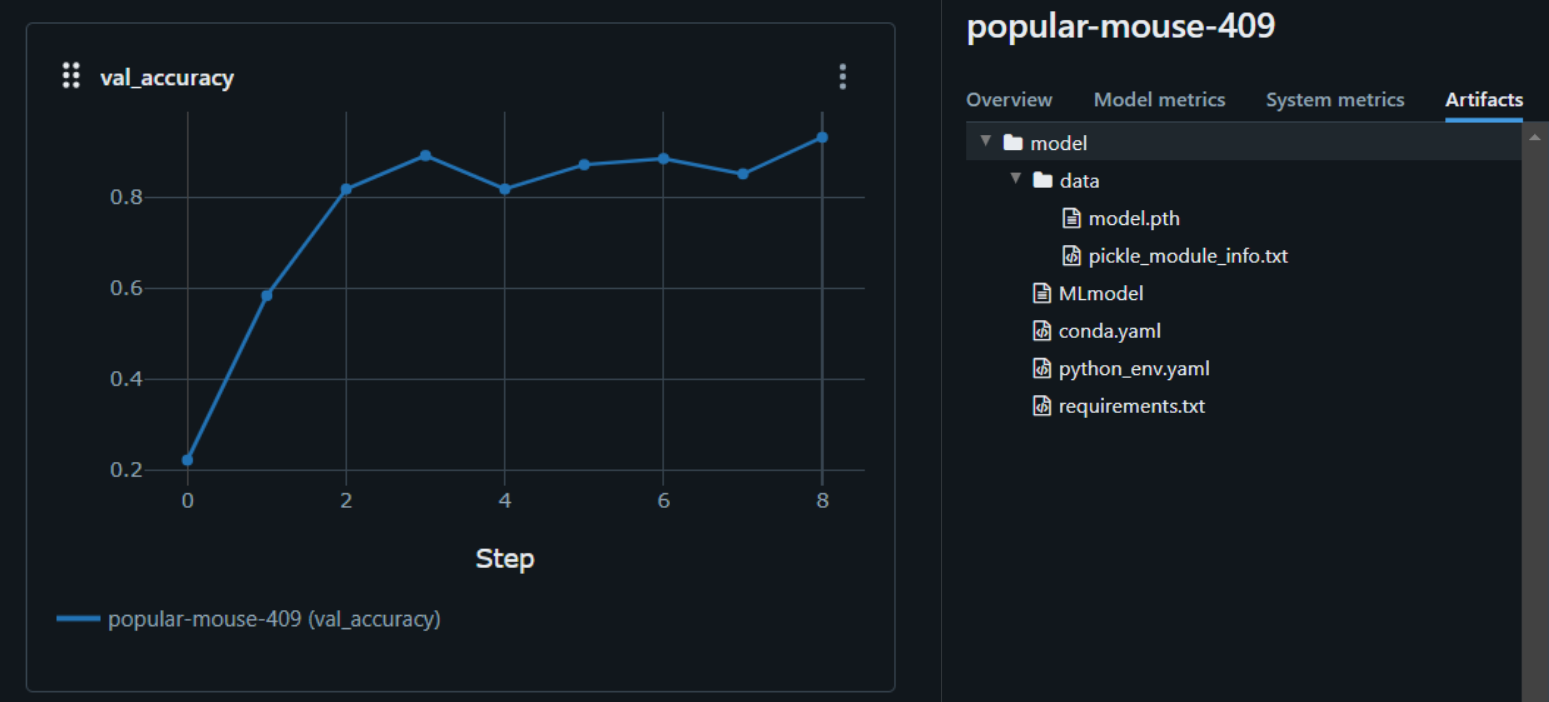
We also benchmarked our results which were satisfactory.
| Area | Benchmark | Dataset | Accuracy | Model | Training Time | Inference Time | Hyperparameters |
|---|---|---|---|---|---|---|---|
| Language | Sentiment Analysis | Financial Sentiment analysis | 81.3 | RoBERTa | 30 min | 30 ms | epochs: 5 optimizer: adam |
| Language | Sentiment Analysis | Financial Sentiment analysis | 63.8 | Custom | 25 min | 40 - 50 ms | epochs:10 |
| Language | Sentiment Analysis | Financial Sentiment analysis | 84 | Transformer | 15 min | 40 ms | Epochs: 15 |
| Language | Translation Spanish to English | English-Spanish | 91.67 | RNN | 40 min | 30 ms | epochs: 20 |
| Language | Translation English to SKannada | English - Kannada | 56.63 | Transformer Arch | 1.5 hrs | 450 ms | epochs: 5 |
| Language | News Classification | BBC News Classification | 97.2 | Parallel ICNN | 26.5 min | 40 ms | LR = 1e-3 dropout=0.5 epochs = 10 ... |
What's Next?
You didn't think we were done, did you? Modelforge is gonna be updated to include CLI with a wide range of commands,this way you can build your model directly from your terminal. We hope to implement parallel processing so our model can handle large-scale operations swiftly and efficiently. But we are most looking forward to making Modelforge open source so ML engineers and data scientists can contribute and enhance our tool.
Whether you’re diving into the world of machine learning for the first time,or you’re refining your next big project,ModelForge is here to make it a lot easier for you and save your precious time. Let’s build something amazing together!!